Course No 2 Using Python to Interact with the Operating System Rough Notes
MAIN COURSE Google IT Automation with Python Professional Certificate
Having 6 crouse
1st course was Python Crash which I have DONE got certificate. My friend say 'bati bana kar gand meen dalo'
Course No 2 Using Python to Interact with the Operating System
------------------------------
By inputting emp name the program will return its email address
In this lab, you will:
- Write a simple test (basic test )to check for basic functionality
- Write a test to check for edge cases by inputting only 1. First name or last name 2. first, last and middle name
- Correct code with a try/except statement
Hayes Delgado,nonummy@abc.edu
Petra Jones,ac@abc.edu
Oleg Noel,noel@abc.edu
Ahmed Miller,ahmed.miller@abc.edu
Macaulay Douglas,mdouglas@abc.edu
Aurora Grant,enim.non@abc.edu
Madison Mcintosh,mcintosh@abc.edu
Montana Powell,montanap@abc.edu
Rogan Robinson,rr.robinson@abc.edu
Simon Rivera,sri@abc.edu
Benedict Pacheco,bpacheco@abc.edu
Maisie Hendrix,mai.hendrix@abc.edu
Xaviera Gould,xlg@abc.edu
Oren Rollins,oren@abc.edu
Flavia Santiago,flavia@abc.edu
Jackson Owens,jacksonowens@abc.edu
Britanni Humphrey,britanni@abc.edu
Kirk Nixon,kirknixon@abc.edu
Bree Campbell,breee@abc.edu
Getting Ready for the Final Project
1.understanding Problem defination
2. Research
3. Planning
SU abssite /var/adm => cat syslog | cut -d' ' -f1| uniq -c
324 Jul
265 Aug
109 Sep
74 Oct
258 Nov
134 Dec
98 Jan
54 Feb
52 Mar
52 Apr
121 May
130 Jun
152 Jul
446 Aug
159 Sep
-----------------------------------------------------------------------
Bash Scripting (Linux) Resources
Check out the following links for more information:
https://linuxconfig.org/bash-scripting-tutorial-for-beginners
------------------------------------------------
-----------------------------------------------------~/Week-6$ cat fruits.sh for fruit in orange mango banana tomatoooo do echo I like $fruit done ~/Week-6$ ./fruits.sh I like orange I like mango I like banana I like tomatoooo ~/Week-6$
- ~/Week-6$ cat random-exit.py
#!/usr/bin/env python3
import sys
import random
value=random.randint(0,5)
print('exit=',(value))
sys.exit(value) - ---------------------------------
- ~/Week-6$ cat trycmd.sh n=0 command=$1 while ! $command && [ $n -le 5 ] #while ! $command ; do ((n+=1)) #sleep $n echo Tried:$n done ~/Week-6$
- -----
------------------------------------------------------------------------
- ~/Python$ cat loop.sh n=1 while [ $n -le 5 ]; do echo $n ((n+=1)) done
- ----------------------------
cut -dseparator -ffields file: for each line in the given file, splits the line according to the given separator and prints the given fields (starting from 1)
------------------------------------------------------

Way to go! This is a practical application of using Python (and some extra hardware, in this case) to automate a task, freeing up a human's time. The solutions can be complex if the return in saved human time warrants it.
-------------------------------------------
--------------------------
ds=shutil.disk_usage('/')
df
usage(total=1760680976384, used=44638605312, free=1626529214464)
df.total,df.used,df.free
(1760680976384, 44638605312, 1626529214464)
--------------------------------------------------------
When a try block is not able to execute a function, which of the following return examples will an exception block most likely NOT return?
Awesome! An exception is not meant to produce an error, but to bypass it.
-----------------------------------------------------------------------------------
Test the software ability and behavious under strees conditions
Way to go! Load testing verifies the behavior of the software remains consistent under conditions of significant load.
----------------------------------------------------------------
_______A test written after bug is identified
Excellent! Regression testing is a type of software test used to confirm that a recent program or code change has not adversely affected existing features, by re-executing a full or partial selection test cases.
Verifying an automation script works well in the overall system and external entities which type test.
Great job! This test verifies that the different parts of the overall system interact as expected.
---------------------------------------------------------------
------------------------------------------
Manual Testing and Automated Testing
1. Manual
2. Automated
What module can you load to use a bunch of testing methods for your unit tests?
Nice job! This module provides a TestCase class with a bunch of testing methods.
The advantage of running automated tests is that they will always get the same expected ___ if the software code is good.
Way to go! Automatic tests will always get the same expected result if the software code is good.
What module can you load to use a bunch of testing methods for your unit tests?
Nice job! This module provides a TestCase class with a bunch of testing methods.
#!/usr/bin/env python3
import sys
import os
import re
def error_search(log_file):
error = input("What is the error? ")
returned_errors = []
with open(log_file, mode='r',encoding='UTF-8') as file:
for log in file.readlines():
error_patterns = ["error"]
for i in range(len(error.split(' '))):
error_patterns.append(r"{}".format(error.split(' ')[i].lower()))
if all(re.search(error_pattern, log.lower()) for error_pattern in error_patterns):
returned_errors.append(log)
file.close()
return returned_errors
def file_output(returned_errors):
with open(os.path.expanduser('~') + '/data/errors_found.log', 'w') as file:
for error in returned_errors:
file.write(error)
file.close()
if __name__ == "__main__":
log_file = sys.argv[1]
returned_errors = error_search(log_file)
file_output(returned_errors)
sys.exit(0)
=========
--------------------------------------------------------
July 31 22:05:31 mycomputername process[37921]: ERROR Process failed
July 31 22:07:54 mycomputername cacheclient[12017]: ERROR Process failed
July 31 22:14:37 mycomputername utility[78832]: INFO Healthy resource usage
July 31 22:22:34 mycomputername updater[78750]: ERROR ID: 10t
July 31 22:41:00 mycomputername jam_tag=psim[40956]: ERROR The cake is a lie!
July 31 22:42:51 mycomputername NetworkManager[28895]: INFO I'm sorry Dave. I'm afraid I can't do that
July 31 23:15:22 mycomputername jam_tag=psim[75013]: ERROR Failed process [13966]
July 31 23:17:05 mycomputername system[88316]: ERROR 418: I'm a teapot
July 31 23:20:09 mycomputername system[42918]: ERROR Out of ink
July 31 23:28:49 mycomputername utility[40452]: INFO Checking process [16121]
July 31 23:29:25 mycomputername utility[22941]: WARN Failed to start CPU thread[39016]
July 31 23:30:46 mycomputername process[99294]: WARN Computer needs to be turned off and on again
July 31 23:35:49 mycomputername dhcpclient[10726]: INFO Googling the answer
July 31 23:36:29 mycomputername updater[86053]: ERROR AssertionError 'False' is not 'True'
July 31 23:40:05 mycomputername utility[88068]: INFO Generating Logs
July 31 23:48:17 mycomputername CRON[28813]: WARN Please send help I am stuck inside the internet
July 31 23:53:58 mycomputername CRON[59985]: INFO Successfully connected
==================syslog data file===================================sysl
no usr in 2nd line
12345678910111213141516171819
Jul 6 14:01:23 computer.name CRON[29440]: USER (good_user)
Jul 6 14:02:08 computer.name jam_tag=psim[29187]: (UUID:006)
Jul 6 14:03:01 computer.name CRON[29440]: USER (naughty_user)
Jul 6 14:03:40 computer.name cacheclient[29807]: start syncing from \
Jul 6 14:04:01 computer.name CRON[29440]: USER (naughty_user)
Jul 6 14:05:01 computer.name CRON[29440]: USER (naughty_user)
-------------------------------------------------
import re
import sys
logfile = sys.argv[1]
print(sys.argv[0])
names={}
with open(logfile) as f:
for line in f.readlines():
if 'USER' not in line:
continue
#Jul 6 14:01:23 computer.name CRON[29440]: USER (good_user)
#r=re.search(r'.*(\d\d:\d\d:\d\d).*USER \((\w+)\)$',line)
r=re.search(r'.*(\d\d:\d\d:\d\d).*USER \((\w+)\)$',line)
if r!=None:
names[r[2]]=names.get(r[2],0) +1
print(r[1],r[2])
print(names)
--------------------------------------
d={}
d['a']=d.get('a',0) + 1 if no value exist add 0 as default value and plus 1
Again, we're taking the current value in the dictionary by passing a default value of zero, so that when the key is in present in the dictionary, we had a default value. We then add one and set it as a new value associated with that key.
============-------
We're using the same syslog, and we want to display the date, time, and process id that's inside the square brackets. We can read each line of the syslog and pass the contents to the show_time_of_pid function. Fill in the gaps to extract the date, time, and process id from the passed line, and return this format: Jul 6 14:01:23 pid:29440.
pattern = r'([A-Z]\w\w \d \d\d:\d\d:\d\d) .*\[(\d{5})\].*'
return result[1]+' pid:'+result[2]
----------------------------------------------------
Obtaining the Output of a System Command
>>> import subprocess
>>> r=subprocess.run(['host','8.8.8.8'],capture_output=True)
>>> r.stdout
b'8.8.8.8.in-addr.arpa domain name pointer dns.google.\n'
>>> 'google' in r.stdout.decode()
True
------------------------------------------------------
Running System Commands in Python
>>> import subprocess>>> subprocess.run(['date'])Thu Sep 7 03:27:02 UTC 2023CompletedProcess(args=['date'], returncode=0)
>> subprocess.run(['sleep','5'])CompletedProcess(args=['sleep', '5'], returncode=0)
Working with Regular Expressions QWICK LAB
Introduction
It's time to put your new skills to the test! In this lab, you'll have to find the users using an old email domain in a big list using regular expressions. To do so, you'll need to write a script that includes:
- Replacing the old domain name (abc.edu) with a new domain name (xyz.edu).
- Storing all domain names, including the updated ones, in a new file.
You'll have 90 minutes to complete this lab.
Start the lab
<csv_file_location> by the path to the user_emails.csv. <csv_file_location> is similar to the path /home/<username>/data/user_emails.csv. For variable report_file, replace <data_directory> by the path to /data directory. <data_directory> is similar to the path /home/<username>/data. Replace <username> with the one mentioned in the Connection Details Panel on the left-hand side.------------------------------


SOURCE CODE ONLY AGAIN AS UNDERimport redef transform_record(record):new_record = re.sub("([\d-]+)",r"+1-\1" ,record)return new_record
Positive Lookbehind: (?<=)
For example, we want to select the price value in the text. Therefore, to select only the number values that are preceded by $, we need to write the positive lookbehind expression (?<=) before our expression. Add \$ after the = sign inside the parenthesis.
Negative Lookahead: (?!)
For example, we want to select numbers other than the hour value in the text. Therefore, we need to write the negative look-ahead (?!) expression after our expression to select only the numerical values that do not have PM after them. Include PM after the ! sign inside the parentheses.
Positive Lookahead: (?=)
For example, we want to select the hour value in the text. Therefore, to select only the numerical values that have PM after them, we need to write the positive look-ahead expression (?=) after our expression. Include PM after the = sign inside the parentheses.
+ 1 or more mathcing "he.*o"
? 0 or 1 occurance "he.?o"
* 0 or many occurance "he.*o"
-----------------------------------------
txt='br ber beer'
------------------------------------------------
print(re.search(r'A.*a','Argentenia'))
-------------------------------
--------------------------------------------------------------------
QUESTION
Fill in the code to check if the text passed has at least 2 groups of alphanumeric characters (including letters, numbers, and underscores) separated by one or more whitespace characters.
----------------------RE Regular expression------
RegEx Functions
Taken from https://www.w3schools.com/python/python_regex.asp
The re module offers a set of functions that allows us to search a string for a match:
| Function | Description |
|---|---|
| findall | Returns a list containing all matches |
| search | Returns a Match object if there is a match anywhere in the string |
| split | Returns a list where the string has been split at each match |
| sub | Replaces one or many matches with a string |
Metacharacters
Metacharacters are characters with a special meaning:
| Character | Description | Example | Try it |
|---|---|---|---|
| [] | A set of characters | "[a-m]" | |
| \ | Signals a special sequence (can also be used to escape special characters) | "\d" | |
| . | Any character (except newline character) | "he..o" | |
| ^ | Starts with | "^hello" | |
| $ | Ends with | "planet$" | |
| * | Zero or more occurrences | "he.*o" | |
| + | One or more occurrences | "he.+o" | |
| ? | Zero or one occurrences | "he.?o" | |
| {} | Exactly the specified number of occurrences | "he.{2}o" | |
| | | Either or | "falls|stays" | |
| () | Capture and group |
Special Sequences
A special sequence is a \ followed by one of the characters in the list below, and has a special meaning:
| Character | Description | Example | Try it |
|---|---|---|---|
| \A | Returns a match if the specified characters are at the beginning of the string | "\AThe" | |
| \b | Returns a match where the specified characters are at the beginning or at the end of a word (the "r" in the beginning is making sure that the string is being treated as a "raw string") | r"\bain" r"ain\b" | |
| \B | Returns a match where the specified characters are present, but NOT at the beginning (or at the end) of a word (the "r" in the beginning is making sure that the string is being treated as a "raw string") | r"\Bain" r"ain\B" | |
| \d | Returns a match where the string contains digits (numbers from 0-9) | "\d" | |
| \D | Returns a match where the string DOES NOT contain digits | "\D" | |
| \s | Returns a match where the string contains a white space character | "\s" | |
| \S | Returns a match where the string DOES NOT contain a white space character | "\S" | |
| \w | Returns a match where the string contains any word characters (characters from a to Z, digits from 0-9, and the underscore _ character) | "\w" | |
| \W | Returns a match where the string DOES NOT contain any word characters | "\W" | |
| \Z | Returns a match if the specified characters are at the end of the string | "Spain\Z" |
Sets
A set is a set of characters inside a pair of square brackets [] with a special meaning:
| Set | Description | Try it |
|---|---|---|
| [arn] | Returns a match where one of the specified characters (a, r, or n) is present | |
| [a-n] | Returns a match for any lower case character, alphabetically between a and n | |
| [^arn] | Returns a match for any character EXCEPT a, r, and n | |
| [0123] | Returns a match where any of the specified digits (0, 1, 2, or 3) are present | |
| [0-9] | Returns a match for any digit between 0 and 9 | |
| [0-5][0-9] | Returns a match for any two-digit numbers from 00 and 59 | |
| [a-zA-Z] | Returns a match for any character alphabetically between a and z, lower case OR upper case | |
| [+] | In sets, +, *, ., |, (), $,{} has no special meaning, so [+] means: return a match for any + character in the string |
Question
<re.Match object; span=(0, 1), match='P'>
print(re.search('P.*','Python is programming'))
<re.Match object; span=(0, 21), match='Python is programming'>
print(re.search('P.*n','Python is programming'))
<re.Match object; span=(0, 20), match='Python is programmin'>
<re.Match object; span=(0, 6), match='Python'>
-----------------------
matching searches.
print(re.findall('cat|dog','I like both dogs and cats')
['dog','cat']
--------------------------------------------------------------
want to search either cat OR dog we have to use pipe |
| pipe symbol
r=re.search('cat|dog','I like cats')
out put wil be like
<re.Match object; span=(7, 10), match='cat'>
-----------------------------------------------------
we want sometime must not be in a text group for we use
circumflex ^ inside the brakets [] like
[^]
r=re.search('[^a-zA-Z]','This is sentences with spaces.')
output will be <re.Match object; span=(4, 5), match=' '>
means at 4the index (start from 0) find a space character which is not
in [a-zA-Z]
if do not want even space match then we will add space in
[a-zA-Z] as [a-zA-Z ]
r=re.search('^a-zA-Z ],'This is sentence is with spaces.')
out put will be <re.Match object; span=(29, 30), match='.'>
----------------------------------------
import os
result=re.search(r'aza','plaza')
print(result)
<re.Match object; span=(2, 5), match='aza'>
result=re.search(r'aza','bazaar')
<re.Match object; span=(1, 4), match='aza'>
r=re.search(r'aza','saeed')
r
print(r)
None
result=re.search(r'^x)
To match any punctuation in the text
r=re.search([;.,!:?],text)
-------------------------------
grep command linux
$ grep ^fruits /home/user/data/words ^ is caret / circumflex
fruitscake
fruitsfull
fruitsed
Using the terminal, which of the following commands will correctly use grep to find the words “sling” and “sting” (assuming they are in our file, file.txt)?
Nice work! In regex, a dot is a wildcard, so it can represent any character. This command will print both “sting” and “sling”, if they are in the file.
import re
Rather than using the index() function of the string module, we can use regular expressions, which are more flexible. After importing the regular expression module re, what regex function might be used instead of standard methods?
Great job! Using the re module provides more robust solutions, not limited to just re.search().
------------------------------------------------------------
I made following project from my brain as under: a simple approach
with open('employees.csv') as normalfile:
# open file as csv.DictReader()
csvfile = csv.DictReader(normalfile)
depts=[]
for row in csvfile:
i+=1
depts.append(row['Department'] )
setdepts = set(depts)
for dept in setdepts:
TOTAL=depts.count(dept)
print(dept,TOTAL)
Option 1: Windows Users: Connecting to your VM
In this section, you will use the PuTTY Secure Shell (SSH) client and your VM’s External IP address to connect.
Download your PPK key file
You can download the VM’s private key file in the PuTTY-compatible PPK format from the Qwiklabs Start Lab page. Click on Download PPK.
Connect to your VM using SSH and PuTTY
You can download Putty from here
In the Host Name (or IP address) box, enter username@external_ip_address.
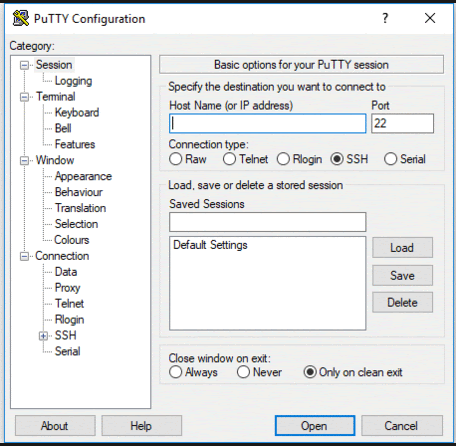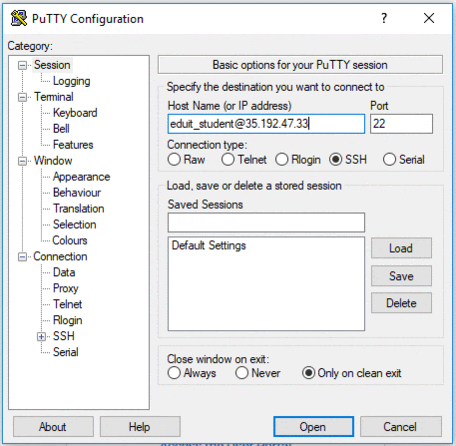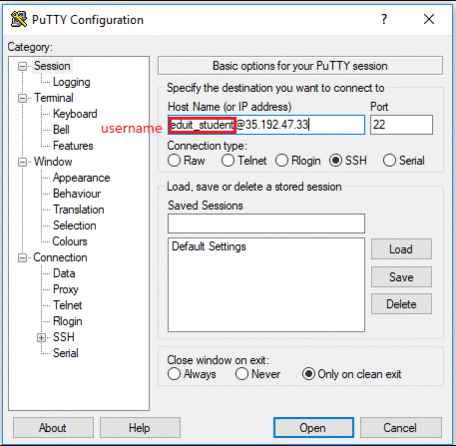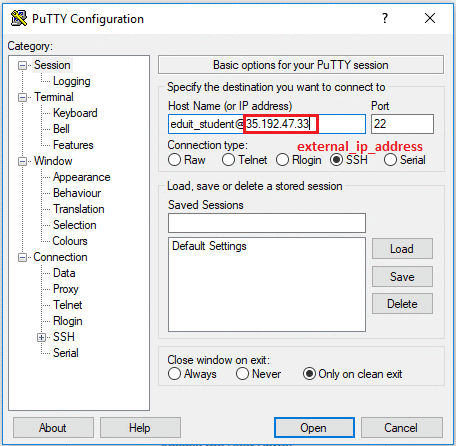
In the Connection list, expand SSH.
Then expand Auth by clicking on + icon.
Now, select the Credentials from the Auth list.
In the Private key file for authentication box, browse to the PPK file that you downloaded and double-click it.
Click on the Open button.
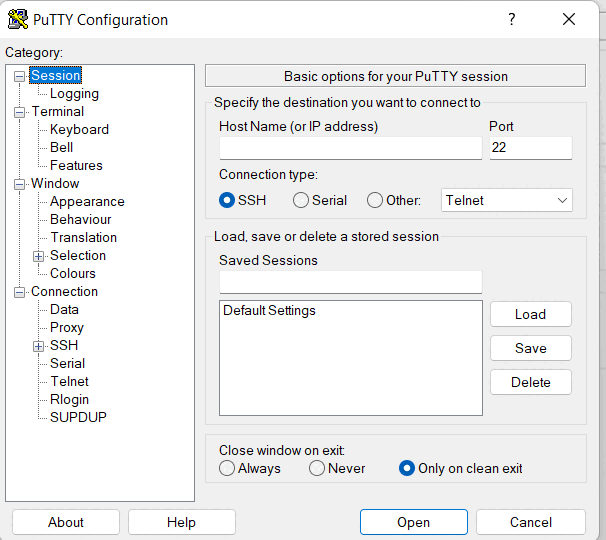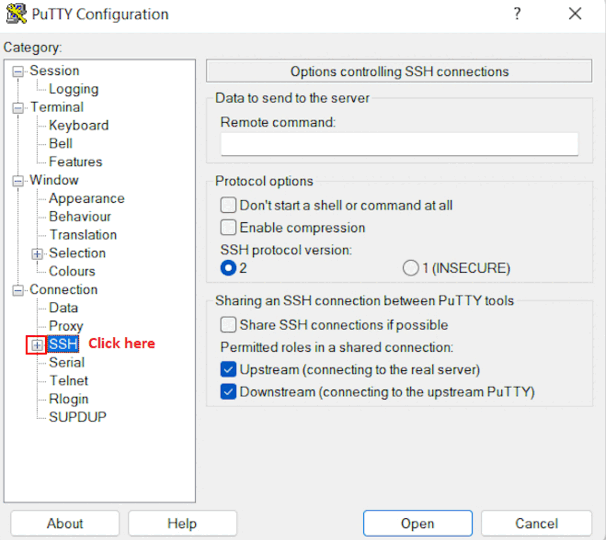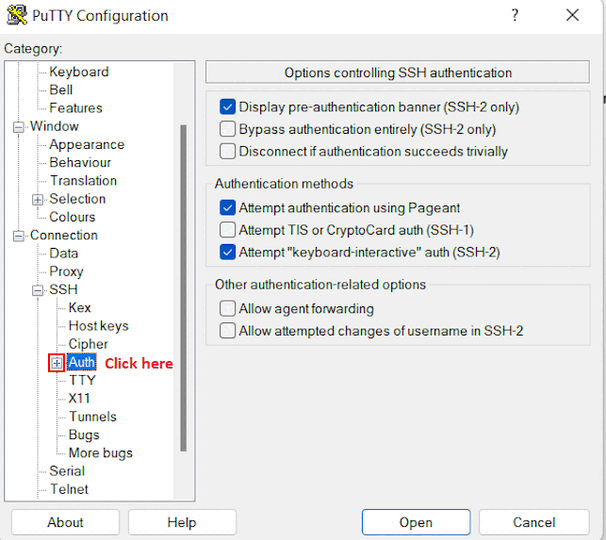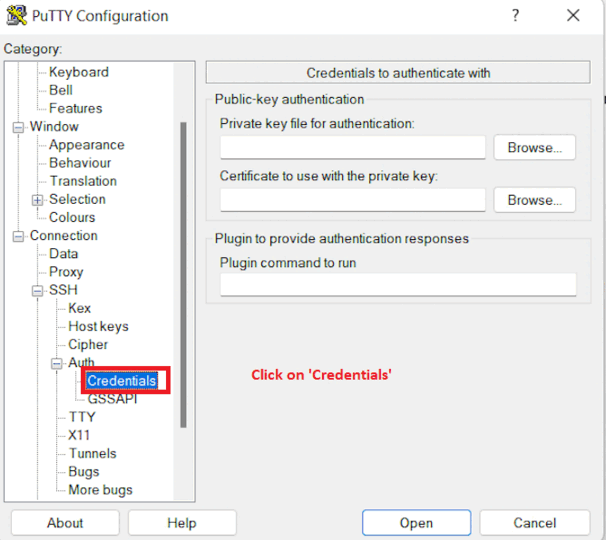
- Click Yes when prompted to allow a first connection to this remote SSH server. Because you are using a key pair for authentication, you will not be prompted for a password.
Common issues
If PuTTY fails to connect to your Linux VM, verify that:
You entered <username>@<external ip address> in PuTTY.
You downloaded the fresh new PPK file for this lab from Qwiklabs.
You are using the downloaded PPK file in PuTTY.
Prerequisites
We have created the employee list for you. Navigate to the data directory using the following command:
cd data
To find the data, list the files using the following command:
ls
You can now see a file called employees.csv, where you will find your data. You can also see a directory called scripts. We will write the python script in this directory.
To view the contents of the file, enter the following command:
cat employees.csv
Let's start by writing the script. You will write this python script in the scripts directory. Go to the scripts directory by using the following command:
cd ~/scripts
Create a file named generate_report.py using the following command:
nano generate_report.py
You will write your python script in this generate_report.py file. This script begins with a line containing the #! character combination, which is commonly called hash bang or shebang, and continues with the path to the interpreter. If the kernel finds that the first two bytes are #! then it uses the rest of the line as an interpreter and passes the file as an argument. We will use the following shebang in this script:
#!/usr/bin/env python3
Convert employee data to dictionary
The goal of the script is to read the CSV file and generate a report with the total number of people in each department. To achieve this, we will divide the script into three functions.
Let's start with the first function: read_employees(). This function receives a CSV file as a parameter and returns a list of dictionaries from that file. For this, we will use the CSV module.
The CSV module uses classes to read and write tabular data in CSV format. The CSV library allows us to both read from and write to CSV files.
Now, import the CSV module.
import csv
Define the function read_employees. This function takes file_location (path to employees.csv) as a parameter.
def read_employees(csv_file_location):
Open the CSV file by calling open and then csv.DictReader.
DictReader creates an object that operates like a regular reader (an object that iterates over lines in the given CSV file), but also maps the information it reads into a dictionary where keys are given by the optional fieldnames parameter. If we omit the fieldnames parameter, the values in the first row of the CSV file will be used as the keys. So, in this case, the first line of the CSV file has the keys and so there's no need to pass fieldnames as a parameter.
We also need to pass a dialect as a parameter to this function. There isn't a well-defined standard for comma-separated value files, so the parser needs to be flexible. Flexibility here means that there are many parameters to control how csv parses or writes data. Rather than passing each of these parameters to the reader and writer separately, we group them together conveniently into a dialect object.
Dialect classes can be registered by name so that callers of the CSV module don't need to know the parameter settings in advance. We will now register a dialect empDialect.
csv.register_dialect('empDialect', skipinitialspace=True, strict=True)The main purpose of this dialect is to remove any leading spaces while parsing the CSV file.
The function will look similar to:
employee_file = csv.DictReader(open(csv_file_location), dialect = 'empDialect')
You now need to iterate over the CSV file that you opened, i.e., employee_file. When you iterate over a CSV file, each iteration of the loop produces a dictionary from strings (key) to strings (value).
Append the dictionaries to an empty initialised list employee_list as you iterate over the CSV file.
employee_list = []
for data in employee_file:
employee_list.append(data)Now return this list.
return employee_list
To test the function, call the function and save it to a variable called employee_list. Pass the path to employees.csv as a parameter to the function. Print the variable employee_list to check whether it returns a list of dictionaries.
employee_list = read_employees('<file_location>')
print(employee_list)Replace <file_location> with the path to the employees.csv (this should look similar to the path /home/<username>/data/employees.csv). Replace <username> with the one mentioned in Connection Details Panel at left hand side.
Save the file by clicking Ctrl-o, Enter, and Ctrl-x.
For the file to run it needs to have execute permission (x). Let's update the file permissions and then try running the file. Use the following command to add execute permission to the file:
chmod +x generate_report.py
Now test the function by running the file using the following command:
./generate_report.py
The list employees_list within the script should return the list of dictionaries as shown below.

Click Check my progress to verify the objective.
Process employee data
The second function process_data() should now receive the list of dictionaries, i.e., employee_list as a parameter and return a dictionary of department:amount.
Open the file generate_report.py to define the function.
nano generate_report.py
def process_data(employee_list):
This function needs to pass the employee_list, received from the previous section, as a parameter to the function.
Now, initialize a new list called department_list, iterate over employee_list, and add only the departments into the department_list.
department_list = []
for employee_data in employee_list:
department_list.append(employee_data['Department'])The department_list should now have a redundant list of all the department names. We now have to remove the redundancy and return a dictionary. We will return this dicationary in the format department:amount, where amount is the number of employees in that particular department.
department_data = {}
for department_name in set(department_list):
department_data[department_name] = department_list.count(department_name)
return department_dataThis uses the set() method, which converts iterable elements to distinct elements.
Now, call this function by passing the employee_list from the previous section. Then, save the output in a variable called dictionary. Print the variable dictionary.
dictionary = process_data(employee_list) print(dictionary)
Save the file by clicking Ctrl-o, Enter, and Ctrl-x.
Now test the function by running the file using the following command:
./generate_report.py
This should return a dictionary in the format department: amount, as shown below.

Click Check my progress to verify the objective.
Generate a report
Next, we will write the function write_report. This function writes a dictionary of department: amount to a file.
The report should have the format:
<department1>: <amount1>
<department2>: <amount2>
Lets open generate_report.py file to define the function.
nano generate_report.py
def write_report(dictionary, report_file):
This function requires a dictionary, from the previous section, and report_file, an output file to generate report, to both be passed as parameters.
You will use the open() function to open a file and return a corresponding file object. This function requires file path and file mode to be passed as parameters. The file mode is 'r' (reading) by default, so you should now explicitly pass 'w+' mode (open for reading and writing, overwriting a file) as a parameter.
Once you open the file for writing, iterate through the dictionary and use write() on the file to store the data.
with open(report_file, "w+") as f:
for k in sorted(dictionary):
f.write(str(k)+':'+str(dictionary[k])+'\n')
f.close()Now call the function write_report() by passing a dictionary variable from the previous section and also passing a report_file. The report_file passed within this function should be similar to /home/<username>/data/report.txt. Replace <username> with the one mentioned in Connection Details Panel at left-hand side.
write_report(dictionary, '<report_file>')
Save the file by clicking Ctrl-o, Enter, and Ctrl-x.
Let's execute the script now.
./generate_report.py
This script does not generate any output, but it creates a new file named report.txt within the data directory. This report.txt file should now have the count of people in each department.
Navigate to the data directory and list the files. You should see a new file named report.txt.
cd ~/data
ls
To view the generated report file, use the following command:
cat report.txt
The report file should be similar to the below image.
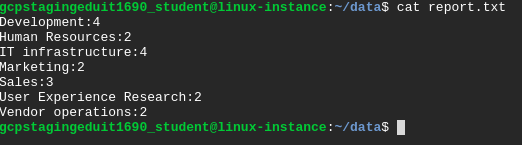
Click Check my progress to verify the objective.
Congratulations!
You successfully wrote a Python script that achieves two tasks. First, it reads a CSV file containing a list of the employees in the organization. Second, it generates a report of the number of people in each department in a plain text file.
Creating reports using Python is a very useful tool in IT support. You will likely complete similar tasks regularly throughout your career, so feel free to go through this lab more than once. Remember, practice makes perfect.
End your lab
When you have completed your lab, click End Lab. Qwiklabs removes the resources you’ve used and cleans the account for you.
You will be given an opportunity to rate the lab experience. Select the applicable number of stars, type a comment, and then click Submit.
---------------------------------------------
Qwiklabs Assessment: Handling Files
Introduction
For this lab, imagine you are an IT Specialist at a medium-sized company. The Human Resources Department at your company wants you to find out how many people are in each department. You need to write a Python script that reads a CSV file containing a list of the employees in the organization, counts how many people are in each department, and then generates a report using this information. The output of this script will be a plain text file.
----------------KWI
How to Log in to Qwiklabs
In the following assessments, you’ll be using Qwiklabs for hands-on learning. Qwiklabs provisions resources backed by Google Cloud that will be used to perform the tasks in the assessments. By using Qwiklabs, you won't have to purchase or install software yourself, and you can use the Linux operating system as if it was installed on your local machine.
Important details:
You will have 90 minutes to complete each lab.
You'll experience a delay as the labs load, as well as for the working instances of Linux VMs. So, please wait a couple of minutes.
Make sure to access labs directly through Coursera and not in the Qwiklabs catalog. If you access labs through the Qwiklabs catalog, you will not receive a grade. (As you know, a passing grade is required to complete the course.)
You'll connect to a new VM for each lab with temporary credentials created for you; these will last only for the duration of the lab.
The grade is calculated when the lab is complete, so be sure to hit "End Lab" when you're done. Note: after you end the lab, you won't be able to access your previous work.
To get familiar with entering labs, find the links below for the operating system of the machine you are currently using for a visualization of the key steps. Note that while video resources linked below do not have a voiceover or any audio, all important details will still be housed in each lab’s set of instructions on the Qwiklabs platform.
If you receive the error "Sorry, your quota has been exceeded for the lab", please submit a request or reach out to the Qwiklabs support team directly via chat support on qwiklabs.com.
-------------------------------------------------------------------------
What is a virtual machine?
Nice job! A virtual machine, or VM, is a computer simulated through software. It simulates all the necessary hardware to the operating system that's running inside the machine.
----------------------------------------------------------------------

-----------------------------------------------------------------

---------------------------------------------------
---------------------------------------------
Name,Age,Location
John,25,New York
Alice,30,Los Angeles
Bob,22,Chicago
# first open file normal with read only
with open('temp.csv') as normalfile:
csvfile=csv.DictReader(normalfile)
for row in csvfile:
print(row)
-------------------------------------------
csv.DictReader() is also a very good Handy function
and also DictWriter() for making Dict csv file
---------------------------------------------
import csv
# Sample list of data get from chatGPT
data_list = [
['Name', 'Age', 'Location'],
['John', 25, 'New York'],
['Alice', 30, 'Los Angeles'],
['Bob', 22, 'Chicago']
]
# open file normal as 'w' permissions
with open('temp.csv','w',newline='') as normalfile:
csvfile = csv.writer(normalfile)
# first thing that you will addrows() not addrows but is writerows()
# addrows() not addrows but writerows()
# First question will be arose the where are the rows/list to be added
# that are om data_list so we will write
# writerows(data_list)
# Second Question in which we writerows() Answer will in csvfile
csvfile.writerows(data_list) # csvfile is already made by above statement BUS (STOP in urdu/hindi), STOP
with open('temp.csv') as f:
csvfile = csv.DictReader(f)
#print(csvfile.fieldnames())
for row in csvfile:
print(row)
print(row["Name"],row["Age"],row["Location"])
-----------------------------------
For writing in or making new csv file
f=open('file.csv','w')
f.csv.writerows(emp)
For reading csv file
----------------------------------------
Which of the following must we do before using the csv.writer() function?
Nice work! The file must be open, preferably using with open() as, and write permissions must be given.
--------------------------------------------------------
Which of the following lines would correctly interpret a CSV file called "file" using the CSV module? Assume that the CSV module has already been imported.
-------------------------------------------------------------------
PARSING : is analysing the contents of a file to collect correct data structure
if we have data in a format we understand, then we have what we need to parse the information from the file. What does parsing really mean?
-----------------------------------------------------------------------------
some OS module functions used
import os
os.remove(mfilename)
os.rename(oldfile,newfile)
os.path.exists('saeed.txt') if file exist return True / False
os.path.getsize(filename) to check files byte size
os.path.getmtime('temp.py') get modified time O/P will be as under
1693390458.2565691 its a timestamp
timestamp=os.path.getmtime('saeed.txt') m=Modified time
import datetime
datetime.datetime.fromtimestamp(timestamp)
out put will be some thing like
(2023, 8, 30, 15, 14, 18, 256569)
os.path.abspath('temp.txt') give absolute path these types of commands os command can be run is each and every OS like Linux, Unix, Window or Apple Os or Andriod etc.
the path will be given according to each OS No need to recode for each OS. The out put of
command in Windows is like:
f:\\0 Python\\temp.py' Note that one slash is another meaning like in print command \n or \t
if you want to print \ your have to write print('\\') not print('\') it will give syntex error
if run same command
os.path.abspath('saeed.txt') in Linux then out put will be some thing like
/home/user/saeed.txt
this is the power of Python a modern language Once you write code it will be platform (Linux, window, apple OS, Andriod) independent.
os.mkdir('saeed')
os.chdir('saeed')
os.getcwd() Get Current Working |Directory
os.rmdir('saeed.txt')
To check is it directory or File os.path.isdir('temp.txt')
--------------------------------------------------------
Never use absolute path of file in your program Make the program general type so that is may run on all the OSes like Linux , Windows. So use the
import os
os.path functions
like os.path.getcwd()
os.path.chdir
path=os.path.join(os.path.getcwd(),mfile_name)
join function os.path.join(dirname,dirname)
mdir=os.path.join(os.getcwd(),'mdir1','mdir2','mdir3')
the out in windows systems is like
'F:\\0 Python\\mdir1\\mdir2\\mdir3'
if same command is given in Linux then out put would be same thing lik
'/home/user/0 Python/mdir1/mdir2/mdir3'
It means the coding will be plateform independent
Question
Files and Directories Cheat-Sheet
Check out the following links for more information:
try:
print('To check how all errors are by passed')
this is error
except:
pass
============================================================
Week 1 is only some bawas, Python installation, python file.py runing from Os.
with open('file.txt') as f:
after working on file it will automatically closes the file
=============================
read file line by line , to save the memory of computer.
do not use mlines=file.readlines() means read all lines of file in memory var mlines it uses the and occupy the memory of computer
====================================
what is Jupyter Notebook


Comments
Post a Comment